Building common SaaS features à la serverless: Upload a File

Building on the foundation of the previous blog post, by the end of this one you'll have designed a well-architected ©, serverless way of processing files uploaded from your users via the web or mobile clients of your (surely awesome) SaaS app.
A personal announcement
By the way, some unrelated yet wonderful news: my recent blogging hiatus might have something to do with me becoming a father for the first time!

I promise to pick the pace back up going forward 😅
Premise
Suppose that your SaaS app has a feature or use-case that requires some sort of document/file to be processed on the server side.
This could be anything, ranging from fancier business use cases like image recognition ML code if the file is a picture or a .PDF to more common ones like extracting information out of an Excel or CSV file.
Traditionally, that would involve an HTTP POST request from a web or mobile client towards one of your application's web servers with the file in question as part of the network call's payload. The web server would then run the file processing code in-process, using the same pool of hardware resources as everything else in your app, limiting capacity for other users and services in the meantime.
I'll show an alternative way of achieving the same result, without any on-premise computing infrastructure (and it's shortcomings) involved, with all the benefits of serverless computing that we've already covered early in this series.
Assumptions
I'll assume that your application is already making good use of a blob storage service (such as AWS S3), to store and retrieve static assets.
Additionally I'll also assume, for the sake of brevity, that your client-side code already uses the language-your-client-code-is-written-at AWS SDK to create objects in S3 buckets.
Finally, because of the assumption I just made, I'll also assume you have an established way of retrieving objects from S3; memory streams or otherwise.
Design
Good news: Amazon S3 has an Event Notifications system built-in! Check the references section for a detailed read up on it.
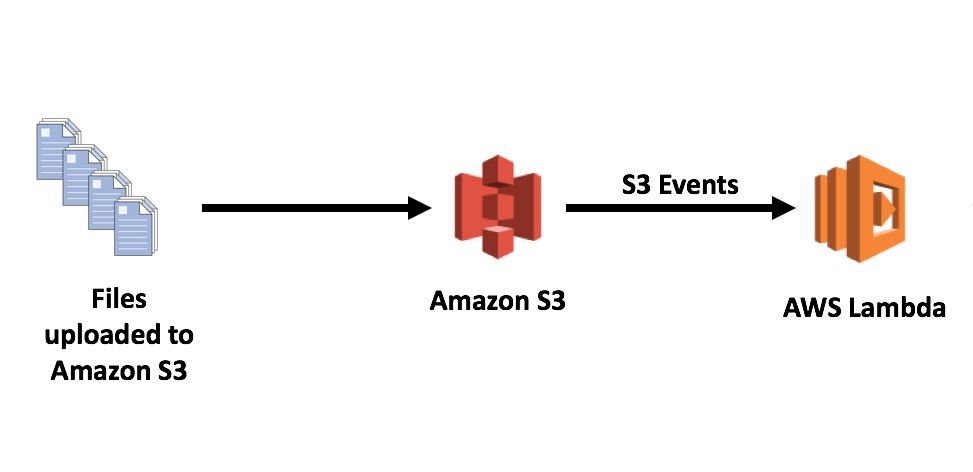
The core idea with the proposed system architecture is that you can leverage a PUT event (that's AWS lingo for creating an object in a S3 bucket) to trigger a Lambda function. Thus your client-side code creating an object in a S3 bucket, can automatically trigger an AWS Lambda function invocation which can process the S3 event payload (that includes metadata as well as the unique URL of the new object in S3) and run business-specific code against this file.
.NET Implementation
Building a reusable Library
We start by creating a .NET Standard 2.1 library project, which will be the dependency which all Lambda functions that need to process S3 events will reference to streamline & standardize the processing of creating or updating objects in an S3 bucket with a connected Lambda function trigger.
Run dotnet new classlib in your command line of choice to create the library.
First, make sure you reference the Amazon.Lambda.S3Events NuGet package.
Building this library on top of the generic event handler function that I talked about on the previous post, we need a contract, one that an actual Lambda function's entry point should be able to call:
public interface
IStorageEventHandler<TS3Event> where TS3Event : class
{
Task HandleAsync(TS3Event s3Event,
ILambdaContext context);
}There's something going on here beyond the provided method; notice the interface's generic constraint: TS3Event needs to be a class (hint: the S3Event class from Amazon.Lambda.S3Events, but also, potentially, any other class that represents a blob storage object).
Next, we'll need to add a reference to our existing generic EventHandler library from the previous post in order to implement the S3EventHandler class that inherits from the IEventHandler<T> interface defined there, where <T> is the S3Event
public class S3EventHandler<TS3Event>
: IEventHandler<S3Event> where TS3Event : class
{
private readonly ILogger _logger;
private readonly IServiceProvider _serviceProvider;
public S3EventHandler(ILoggerFactory loggerFactory,
IServiceProvider serviceProvider)
{
_logger = loggerFactory?.CreateLogger("S3EventHandler")
?? throw new ArgumentNullException(nameof(loggerFactory));
_serviceProvider = serviceProvider
?? throw new ArgumentNullException(nameof(serviceProvider));
}
public async Task HandleAsync(S3Event input,
ILambdaContext context)
{
foreach (var record in input.Records)
{
using (_serviceProvider.CreateScope())
{
var handler = _serviceProvider
.GetService<IStorageEventHandler<TS3Event>>();
if (handler == null)
{
_logger.LogCritical(
$"No INotificationHandler<{typeof(TS3Event).Name}> could be found.");
throw new InvalidOperationException(
$"No INotificationHandler<{typeof(TS3Event).Name}> could be found.");
}
_logger.LogInformation("Invoking notification handler");
await handler.HandleAsync(record as TS3Event, context);
}
}
}
}Pretty straightforward, we just wire up the logging factory & dependency injection services here, add some rudimentary exception handling and asynchronously process each of the available records that constitute the invocation event.
That's all it is! Before we move on to using our new library in a Lambda function .NET project though, it's worth discussing the DI part briefly.
Microsoft has provided it's own implementation of a dependency injection container in .NET (in the form of a NuGet package) since .NET Core 2.1, called Microsoft.Extensions.DependencyInjection.
If you're looking to do DI as part of any library, you'll need to implement the IServiceCollection interface in a static class, so that the framework is able to collect the necessary service descriptors.
For our library, this will look like this 👇🏻
public static class ServiceCollectionExtensions
{
public static IServiceCollection
UseNotificationHandler<TS3Event, THandler>
(this IServiceCollection services)
where TS3Event : class
where THandler : class, IStorageEventHandler<
TS3Event>
{
services.AddTransient<
IEventHandler<S3Event>, S3EventHandler<
TS3Event>>();
services.AddTransient<
IStorageEventHandler<TS3Event>,
THandler>();
return services;
}
}Using the Library with an AWS Lambda .NET project template
Using your favorite shell, install the AWS .NET project templates: dotnet new -i Amazon.Lambda.Templates.
Now let's create an AWS .NET Lambda project: dotnet new lambda.EmptyFunction. Please see the references section for an exhaustive list of the possible arguments for this command.
Next, reference both the generic Event function library as well as the S3 specific one you just created.
Modify Function.cs, which is the entry point for Lambda function invocations as follows:
public class Function : EventFunction<S3Event>
{
protected override void Configure(
IConfigurationBuilder builder)
{
builder.Build();
}
protected override void ConfigureLogging(
ILoggerFactory loggerFactory,
IExecutionEnvironment executionEnvironment)
{
loggerFactory.AddLambdaLogger(new LambdaLoggerOptions
{
IncludeCategory = true,
IncludeLogLevel = true,
IncludeNewline = true
});
}
protected override void ConfigureServices(
IServiceCollection services)
{
// TODO: services registration (DI) &
// environment configuration/secrets
services.UseNotificationHandler<
S3EventNotification,
YourAwesomeImplS3EventHandler>();
}
}Startup.csY'all know exactly what's up above already. All that's left at this point is to create a class to implement your business logic, YourAwesomeImplS3EventHandler.cs.
public class YourAwesomeImplS3EventHandler : IStorageEventHandler<
S3EventNotification>
{
private readonly ILogger<
YourAwesomeImplS3EventHandler> _logger;
public YourAwesomeImplS3EventHandler(
ILogger<YourAwesomeImplS3EventHandler> logger)
{
logger = _logger ??
throw new ArgumentNullException(nameof(logger));
}
public async Task HandleAsync(
S3EventNotification s3Event,
ILambdaContext context)
{
// TODO: your business logic goes here
}
}Once you're done, you can build and deploy using the Amazon.Lambda.Tools .NET Core Global Tool. To install the .NET Core Global Tool, run the following command: dotnet tool install -g Amazon.Lambda.Tools.
Update the tool to it's latest version: dotnet tool update -g Amazon.Lambda.Tools.
With Amazon.Lambda.Tools now installed, you can deploy your function using the following command: dotnet lambda deploy-function MyFunction --function-role role. Please check the references section for details on configuring a relevant AWS IAM role as well as function-specific configuration such as resources & environment variables.
Conclusions
Serverless is badass, people. That's it, that's the conclusion.

Coming up next
In the next post you'll design and implement the serverless equivalent of an extremely common type of application service: a CRON job; code that runs on either a scheduled basis/regular intervals or that is scheduled to run once at some point in the future in *nix-based operating systems.
References



