A better serializer for Lambda

This is the second part of my ongoing ".NET Core 3.1 on AWS Lambda" series, based on the lessons learned from recent experiences while upgrading .NET Core serverless apps from 2.1 to 3.1 in Lambda.
A new library, made available a couple of months ago alongside the 3.1 release on Lambda, will be the focus point: Amazon.Lambda.Serialization.SystemTextJson.
 aws
aws
This package contains a custom Amazon.Lambda.Core.ILambdaSerializer implementation which uses System.Text.Json to serialize/deserialize .NET types in Lambda functions.
Motivation
Let's first establish the why. Why would we want to replace the existing Amazon.Lambda.Serialization.Json library (which is based on Newtonsoft.Json, the by far most popular NuGet package), that has faithfully served us so far in this serverless journey and continues to do so all the same for .NET Core 3.1 out of the box?
It's (demonstrably) faster
To begin with, System.Text.Json's anything between 50% and 100% faster in serializing/deserializing JSON payloads compared to Newtonsoft.Json.
Here are some performance metrics from Microsoft that show just that:
 Immo Landwerth
Immo Landwerth
It's cheaper (in $$$)
This is important for sizeable plain text payloads that other AWS services who act as Lambda triggers, such as SNS/SQS/DynamoDB streams, dump on the entry point of a Lambda function.
Case in point, the following metrics were taken from our serverless monitoring tool (Epsagon) for a .NET Core 3.1 Lambda function that has an SNS topic trigger. I've highlighted the period in the X axis since we re-deployed this Lambda to an AWS environment with the new Amazon.Lambda.Serialization.SystemTextJson serializer.
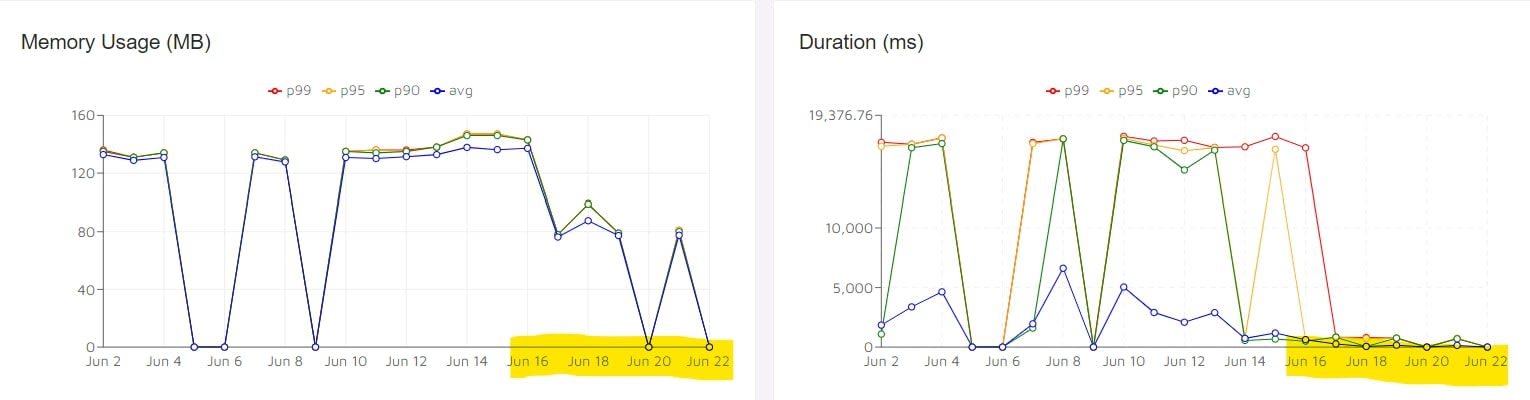
Granted, this particular Lambda function does a lot of deserializing and this sample spans a mere few days of aggregated results but this visualization is a good way to paint a "before and after" picture. And it's not just how faster this is; even RAM usage went down considerably (which is consistent with Microsoft's benchmarks above for larger JSON payloads) both of which mean a lower AWS Lambda bill overall.
Beam me up Scotty!
All one's gotta do to take advantage of these new opportunities is to replace the JSON serialization assembly used in a .NET Core 3.1 Lambda's entry class, from:
[assembly: LambdaSerializer(typeof(Amazon.Lambda.Serialization.Json.JsonSerializer))]
to: [assembly:LambdaSerializer(typeof(Amazon.Lambda.Serialization.SystemTextJson.DefaultLambdaJsonSerializer))]
The rub
If you were unfortunate enough to be an early adopter of this new library, chances are you've encountered this: https://github.com/aws/aws-lambda-dotnet/issues/624

Long story short,Amazon.Lambda.Serialization.Json and System.Text.Json use PascalCase when serializing objects by default. Amazon.Lambda.Serialization.SystemTextJson's first version used camelCase by default. This would affect Lambda functions returning custom response objects, for example in functions used by state machines in AWS Step Functions.
At that point though, the first version of the library had already shipped, so changing the LambdaJsonSerializer class to now use PascalCase might've broken Lambda functions that had already compensated for the change in casing. Instead, a new version of the library was subsequently released, containing a new class called DefaultLambdaJsonSerializer which acts consistently with how System.Text.Json works by default. That means the casing of the .NET properties in the .NET object is what will be used in the output JSON document. If you want the camelCase behavior you can use CamelCaseLambdaJsonSerializer instead of DefaultLambdaJsonSerializer. The LambdaJsonSerializer class has been marked as Obsolete and should not be used going forward.
A detailed write up of this issue as well as other "youth problems" encountered over the first few weeks can be found on the official AWS .NET team's blog:
This is but the beginning of ripping Newtonsoft.Json out of existing .NET Core 3.1 applications deployed on AWS Lambda. It's a low-hanging fruit with a great ROI though, so that's what this post was about.
What's next?
In the next post of this blog series, things are going to get serious: I am going to do a deep-dive on how to get from some System.Text.Json to all System.Text.Json in a .NET Standard 2.1 library that relies heavily on custom Newtonsoft.Json serializers to read data from AWS DynamoDB thus arriving to the promised land of a .NET Core project with no dependencies on Newtonsoft.Json.
p.s. I'm absolutely not bashing on Newtonsoft.Json here, in fact it's an amazing library that takes care of a lot of implementation details for you by being opinionated out-of-the-box. It covers a much broader scope of use-cases than System.Text.Json and for many projects it's not worth undergoing this process without carefully examining the risk vs reward ratio first. In some cases it might not even be possible to replace Newtonsoft.Json with System.Text.Json because the latter doesn't have feature parity with the former (and likely won't ever have because that's not the goal of the designers). But in the serverless world where execution doesn't necessarily occur in-process, speed of execution trumps any other metric and that's what this is about.

